Often when web-crawling you can find access to website's api which provides direct JSON of a product, however it's not always so easy to find what you need in what could be a multi-layer mess of a json.
In this blog-post I'll cover few tools and ways to deal with really ugly json trees that you probably don't want to iterate through manually using dictionary key indices.
If you don't care about the research you can just skip to the right tool and solving of the real life case sections at the end.
Cause
Often websites, especially the ones that sell various products tend to overcomplicate their apis by stacking everything in one huge json tree that is at least 10 layers deep and is impossible to understand for an outsider or maybe even other developers in the company.
In this case we'll take a look at small examples of http://ah.nl responses and how can we deal with them without spending hours trying to reverse engineer the whole process.
Example info:
Product url: http://www.ah.nl/producten/product/wi166580/maggi-opkikker-rundvlees
Product api response: https://ptpb.pw/aZ_S
If you put this response through some json visual tool like http://jsonviewer.stack.hu/ you'll notice what a huge mess it is:
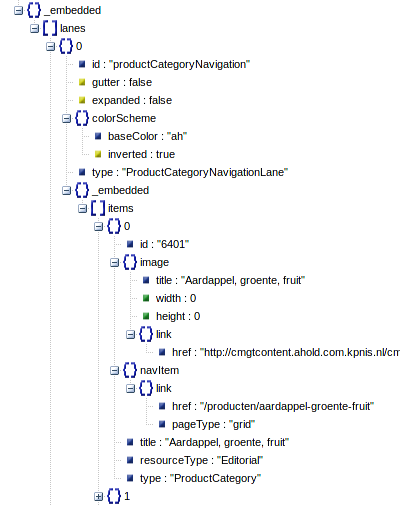
Multiple layers, multiple elements, list in a dict in a list in a dict and to parse that you'd end up doing something like:
import json
data = json.loads(body)
items = data['_embedded']['lanes'][4]['_embedded']['items']
And that's just half-way through the tree. For example to find the sku you'd have to use something like:
sku = data['_embedded']['lanes'][4]['_embedded']['items'][0]['_embedded']['product']['id']
Now that's with hard-coding of list indices which are very likely to change for every product, so on top of that ugly line above you'd have to use multiple list comprehensions to find the correct list item from the lanes or items lists. This is bad, ugly, unreliable and extremely painful to work with.
Tools to Solve This
There are several ways this can be approaches and let me spoil it for you, majority of them are bad, so we'll start off with those.
To demonstrate these tools better we'll be parsing this simple json:
data = """{
"one": {
"two": [{
"four": {
"name": "four1_name"
}
}, {
"four": {
"name": "four2_name"
}
}]
}
}"""
All examples below are also available on iPython notebook if you want to mess around with them yourself here
Wrong: Flattening The Json
At first glance this might appear as an obvious solution - just flatten everything to the first level! However this brings out a huge issue with keys. Because every key has to be unique, when flattening the dictionary you need to merge several keys into one to preserve the tree order.
If we were to flatten our data, it would end up looking like this:
data = """{
"one_two_four1_name": "four1_name",
"one_two_four2_name": "four2_name",
}"""
In a way you might think it looks nice, but the truth is that it's really unpredictable and hard to parse in a more complex context, since you can only select individual values. This might be useful for some edge cases where you only need 1 field the json tree is only two or tree levels deep, but otherwise it's not worth bothering with.
Wrong: Jmespath, JSONPath and JSONiq etc.
These few libraries in a way designed specifically to solve this issue. It seems that json is notoriously bad when it comes to this issue, so tools like theses are dime a dozen on github and while they are great, they fall short when in comes to web-crawling or similar use cases.
However there are two major issues with these tools:
-
First one being that some of them like the very
Jmespath's expressions root-bound which means non-rooted expressions like xpath's//product/nameare not possible. This means that you need to write this ugly chain which is barely different to our dict key indices one:root.foo.bar[].foo2.bar2.product.mynode
The only improvement here is that we can do a bit of recursion by calling [] for every list element, saving us a few list comprehension calls. And it definitely looks nicer, doesn't it?
It is still bad though since at any point the tree might change and our crawler will break because we are root bound.
- The second issue being is that all of them are extremely bloated, to the point where they not only design their own parsing logic but also design their own syntax.
When you are crawling a website you already have your own parsing tools to parse the html/xml (like lxml or parsel) and anything other would just introduce obvious redundancy and unnecessary complexity.
Almost Right: js2xml
First I'd like to start off with and give a shout out to a great tool called js2xml which maintained by Scrapinghub. It pretty much does what it says - converts javascript code to an xml tree and it's almost the right tool for our issue, almost.
Since json is part of javascript, this means we can use this tool to parse it:
from lxml import etree
# we need to wrap our data json in variable declaration
# for js2xml to interpret it
parsed = js2xml.parse('var foo = ' + data)
print(etree.tostring(parsed, pretty_print=True))
This is the result:
<program>
<var name="foo">
<object>
<property name="one">
<object>
<property name="two">
<array>
<object>
<property name="four">
<object>
<property name="name">
<string>four1_name</string>
</property>
</object>
</property>
</object>
<object>
<property name="four">
<object>
<property name="name">
<string>four2_name</string>
</property>
</object>
</property>
</object>
</array>
</property>
</object>
</property>
</object>
</var>
</program>
As you can see it works and could probably be parsed with xpath. It's really ugly and if we were to write an xpath for it, it would be unnecessary complicated and long, but it would work!
If you are already using it to parse javascript somewhere you might just go with it to reduce dependencies if you wish so.
Right: Converting json to xml and Parsing It With xpath
I found two tools and either one of them combined with either lxml or parsel selectors create this beautiful, perfect json-crawling combo for your crawler!
For unaware lxml is a really great tool for parsing xml and html while parsel is built on top of it to make it even greater, so I highly recommend checking it out!
Fun fact - it's also used by scrapy and that's where it originated.
Getting back to the point, the two tools that are pretty much alternative to each other are dicttoxml and dict2xml. They are essentially the same thing but I thought I'd mention both since I'm not sure which one is better and requires the recognition.
For sake of being brief I'll show off dicttoxml + parsel only:
from dicttoxml import dicttoxml
root = dicttoxml(json.loads(data), attr_type=False)
# the tree we get:
<root>
<one>
<two>
<item>
<four>
<name>four1_name</name>
</four>
</item>
<item>
<four>
<name>four2_name</name>
</four>
</item>
</two>
</one>
</root>
Now we can parse this tree using parsel.Selector and xpath:
from parsel import Selector
sel = Selector(text=root.decode('utf-8'))
# and get the names with
sel.xpath("//name/text()").extract()
# ['four1_name', 'four2_name']
Pretty mind blowing how we solved this mess with one 300 loc big package from pypi and one short xpath.
Solving Our Example
Now that we have chosen a tool let's see how well it works on a real life example we got ourselves at the beginning of this blog: http://www.ah.nl/producten/product/wi166580/maggi-opkikker-rundvlees
I'm going to spoil you the joy of reverse engineering the products api and tell you the api url in this case is:
'http://www.ah.nl/service/rest/delegate?url=/producten/product/wi166580/x'
Lets assume we already have the page source in body variable and dive in:
from dicttoxml import dicttoxml
from parsel import Selector
import json
data = json.loads(body)
sel = Selector(text=dicttoxml(data, attr_type=False))
# now we can find things very easily!
# sku:
sel.xpath("//product/id/text()").extract()
# [u'wi166580']
# price:
sel.xpath("//product//pricelabel/now/text()").extract()
# [u'0.82']
Conclusion
Mission accomplished! We managed to parse multi-layer monster with very few, simple xpaths and a small package from pipy!
Personally I wish I started doing this earlier because iterating through monsters like this one key at the time is extremely tedious and it breaks every time the website decides to update something.
Hopefully this write up can save someone few hours and an early balding. :D